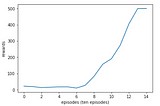
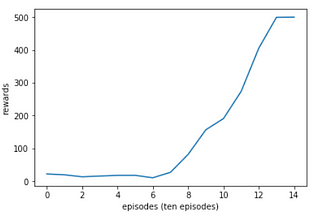
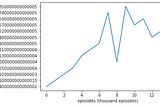
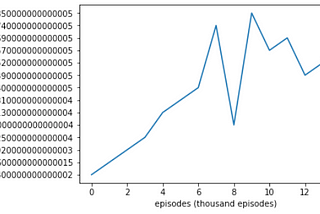
Ahmed El-KhoulyReinforcement Learning Digest Part 4: Deep Q-Network(DQN) and Double Deep Q-Networks(DDQN)In last article, we have discussed Q-learning and we have seen its desirable convergence attributes. Never the less, Q-learning has one…Nov 23, 2020Nov 23, 2020
Ahmed El-KhoulyReinforcement Learning Digest Part 3: SARSA & Q-learningIn the last article I have explained generalized policy iteration process and described our first reinforcement learning algorithm: Mote…Nov 22, 2020Nov 22, 2020
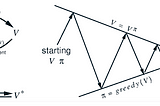
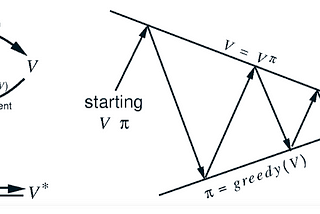
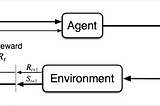
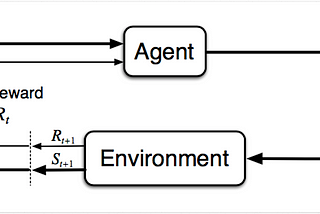
Ahmed El-KhoulyReinforcement Learning: Bellman Equations, GPI and Monte Carlo — Part 2In the last article, I have introduced Reinforcement learning Markov Decision Process (MDP) framework, discounted expected rewards and…Nov 22, 2020Nov 22, 2020